Claude Code Cost Tracking: Token Counters Tell You What You Spent, Not Where It Went
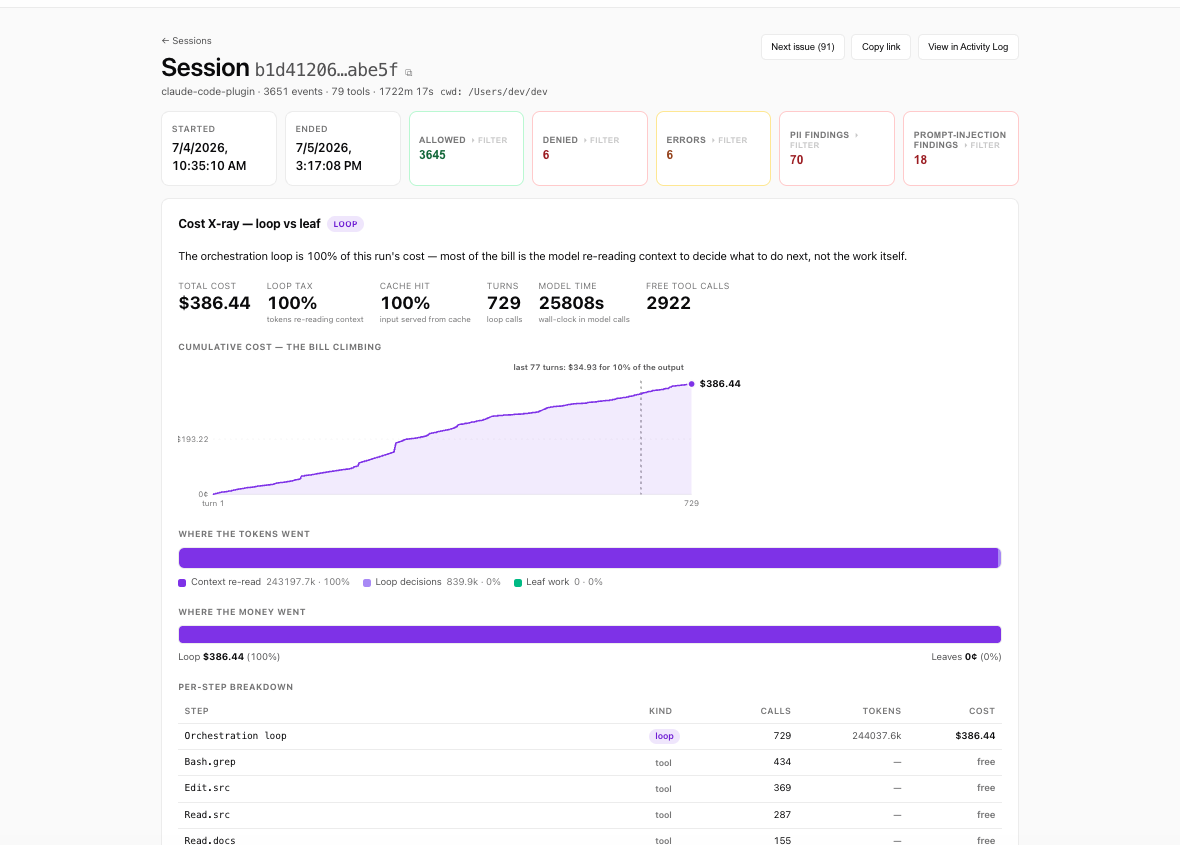
Here’s a real number: one full working day of Claude Code — 276 model calls, 1,697 tool calls — priced out at $148.16 at API rates. On a Max subscription the invoice says nothing like that, which is exactly why the question “what does Claude Code actually cost?” has spawned a small ecosystem of trackers. Most of them are token counters. Token counters answer what you spent. The number that changes behavior is where it went — and for that session, the answer was: 100% loop tax. Not one dollar of it was the model producing answers; all of it was the orchestration loop re-reading 72 million tokens of accumulated context, turn after turn. The last 28 turns of the day bought 10% of the output.
You can’t see any of that in a total. This post is the honest map of the Claude Code cost-tracking options, what each can and can’t tell you, and what per-action attribution adds.
What the token counters do well
Three tiers exist today, and the first two are genuinely useful:
Built-in: /cost. Claude Code will tell you the current session’s token usage on demand. Zero setup, session-scoped, gone when the session is.
Local counters: ccusage and friends. Tools like ccusage read Claude Code’s local session logs and roll them up — daily totals, per-model splits, “how much of my subscription am I using.” If your question is “am I getting my money’s worth from the Max plan?”, a log-reading counter answers it in one command, for free. No proxy, no account, no config. Use one.
LLM proxies. Route Claude Code’s API traffic through a proxy (the LiteLLM-style setup) and you get metered totals per key or per user — the team-level version of the same answer.
All three share a shape: they sum tokens and multiply by price. The unit of accounting is the session or the day. And that’s where they stop.
What a total can’t tell you
The $148 session above looks identical, as a total, to a session where the money bought 276 useful answers. A counter can’t distinguish them, because the expensive thing about an agent isn’t any single call — it’s the structure: the loop re-ingests the whole growing transcript on every turn, so the same tokens get re-billed again and again as the session snowballs. Across 210,840 metered tool calls on our own workspaces, that orchestration loop was 89% of total spend — and one frontier model on the loop drove 80% of the bill from just 7.6% of the calls. We call it the loop tax, and it’s invisible in a sum.
Questions a token counter structurally can’t answer:
- Loop or leaf? Was the spend the model orchestrating (deciding what to do next, re-reading context) or the model working (the sub-task that produced output)?
- Which turn? Where in the session did cost accelerate — and did the last N turns buy anything? (Ours bought 10%.)
- Is caching working? The $148 day ran at a 100% cache hit rate — the only reason it wasn’t roughly 10× more. That’s a per-call property; a total hides both the win and the miss.
- Which action? 1,697 tool calls happened. Which of them triggered the expensive re-reads?
None of those are exotic analytics. They’re the questions you’d ask about any other bill: not just how much, but for what.
Per-action attribution: pricing each call as it happens
The alternative shape is a proxy that doesn’t just meter tokens but tags every call with what it was: which session, which turn, which model, loop or leaf, cache hit or miss, and the dollar cost of that one call — even when you’re on a subscription and the marginal price you pay is $0. (Anthropic bills you exactly as before; your key or subscription passes through untouched. The pricing is a lens, not a charge.)
Then the session ends with a line instead of a mystery:
ACP · session governed: 276 model calls · 1,697 tool calls · $148.16 @ API rates
…and the X-ray behind it shows the cost curve turn by turn. That’s the view where the levers become visible, because the levers that move agent cost are all structural: put a cheaper model on the loop (in our data the frontier model on the loop cost ~114× per call what the cheap model did), verify the cache is actually hitting, and cap the runaway session at turn 30 instead of turn 300. You can’t pull any of those from a daily total — you can pull all of them from a per-action view.
For a subscription user the punchline is different but the same data: $148.16 at API rates against a flat monthly fee is the seats-vs-API decision, settled with your own numbers instead of a forum thread.
The honest recommendation
- Want to know what you spent?
/costor ccusage. Free, local, good. - Want to know what your team spent? A metering proxy with per-key totals.
- Want to know where it went and what to change — loop vs leaf, per turn, per action, priced even on subscription? That’s what ACP’s cost X-ray does for coding agents, and it rides the same install that governs the tool calls:
curl -sf https://agenticcontrolplane.com/install.sh | bash
Plain claude keeps working untouched; claude-acp is the governed, priced variant. And since the proxy sees every request anyway, you get the other half for free: the full declared tool surface of your agent — all 76 tools, captured live in the Tool Surface Index — with every call checked against your allow/deny rules before it runs.
The token counters told you the bill went up. The interesting question was always which turn, which model, and which loop did it — because that’s the version of the answer you can act on.
Cost figures are from our own sessions and workspaces (2026-06/07 snapshots) — dogfood, not customer data.